
In the previous post, we argued that scaling AI inside an enterprise is an operating problem: how tools and data are exposed, controlled, observed, and paid for as usage spreads across teams and environments.
We saw this firsthand throughout 2025 while building alongside design partners who were early to agentic workflows. In almost every case, the pattern was the same: a few proof-of-concepts that looked promising, followed by the hard part—shipping agents that close the loop and deliver reliable outcomes in real systems. That's where the bottlenecks showed up repeatedly: connection sprawl, missing observability, inconsistent permissions, and rising costs without attribution.
Those constraints pushed us toward context infrastructure: treating MCP traffic as a first-class production surface. That's what the MCP Mesh is. We originally built it as an internal layer to ship these systems with customers. This release turns that layer into a self-hosted component and shares it with the open-source community—because many platform teams seem to be running into the same issues.
Once you move beyond a few PoCs, you start paying for MCP integrations in three places at once:
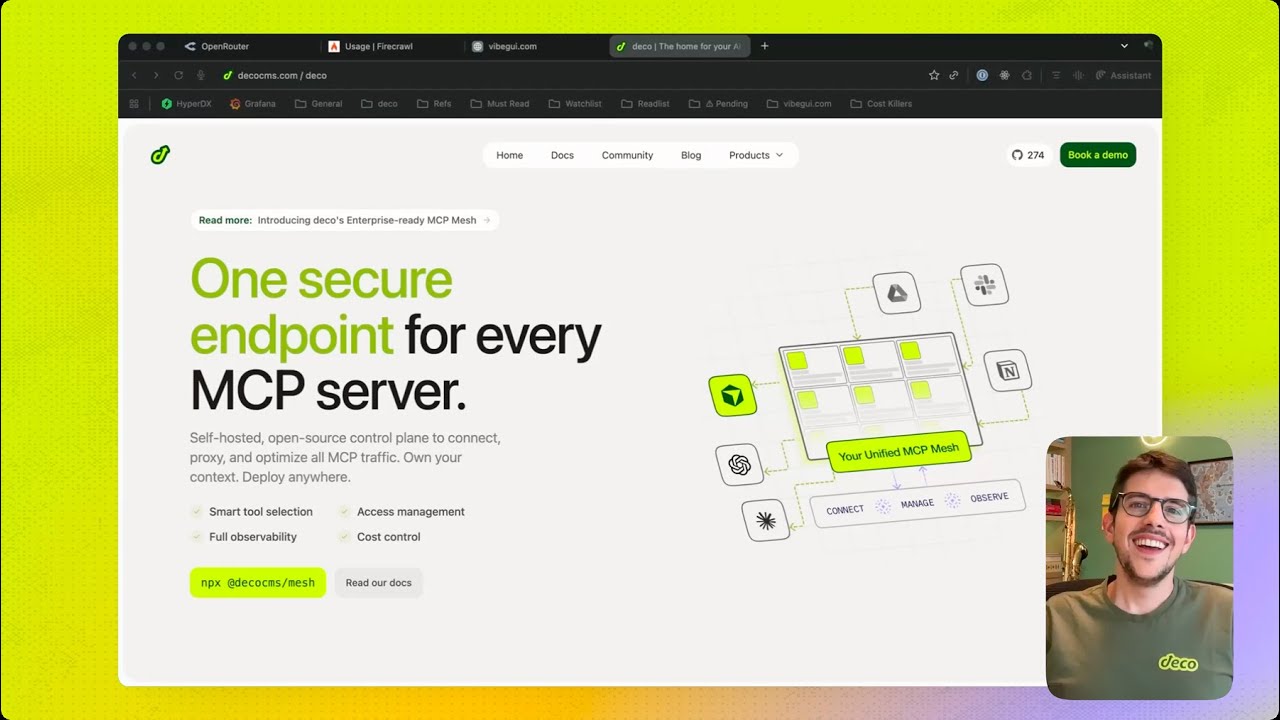
An MCP Mesh is our answer to that: a self-hosted control plane that sits between your apps/agents and your MCP servers, so you can manage MCP traffic like any other production surface—with routing, access control, observability, and runtime strategies.

The MCP Mesh sits between your applications (agents, internal tools, IDE clients) and your MCP servers.
Your code integrates with one endpoint. Behind that endpoint, the mesh can call any MCP server—GitHub, Jira, internal databases, custom tools, even LLM providers exposed as MCP—while centralizing the concerns you don't want reimplemented across every app:
which MCP to call, how to authenticate, how to retry, how to fail
who (team/user/agent) can access which tools and data
logs, traces, latency, errors across MCP calls and model calls
attribution and enforceable guardrails. Coming soon
different ways to expose tools and context depending on latency/cost/accuracy needs
This is the difference between "we connected tools to agents" and "we can operate tool access in production."

First you need it to run end-to-end. Most teams do this with ad hoc integration logic. The mesh is about making that step fast without creating long-term sprawl.
The mesh is self-hosted by design with zero-config for local setup.
Other typical setups:
Instead of managing eight MCP server connections in your client—each with separate config and auth—you configure one endpoint. All your organization's MCP traffic flows through it.
We also support dev-time tunneling (deco.host) so you can run and test MCP servers locally during development without publishing them.

Once it works, it needs to work reliably, securely, and predictably.
This is where teams typically discover they don't just need "an MCP aggregator"—they need a control plane.
When something breaks, you can see the chain: which MCP call failed, how long it took, what it returned, and what happened next.
Token-level cost tracking by team/user/agent/application, plus guardrails like budget caps and rate limits.
Role-based access control at the model, MCP, and tool level. Policies enforced at the control plane, not duplicated across apps. Audit logs suitable for regulated environments.
The goal is to make "safe by default" the easiest path.
Once agents run in production, a new problem shows up: they work, but they get slow and expensive as tool surfaces grow.
The naive approach is to describe every tool to the model on every call. That's workable with a small toolset. It breaks when you have dozens of MCP servers and hundreds of tools: context balloons, latency climbs, and tool selection gets harder.
Concrete example: 50 MCPs × 10 tools each = 500 tools. Even if descriptions are short, you can spend a meaningful chunk of the context window just listing capabilities—paying in tokens and time, often with worse tool selection.
Internally, we started modeling "runtime strategies" as gateway implementations.
A gateway still gives you one endpoint (usable from Cursor, Claude Desktop, internal agents, etc.), but it changes how tools are exposed:
expose everything, always. Simple, deterministic, best for small tool surfaces.
a two-stage approach that narrows the toolset before execution.
instead of describing tools in detail, let the model write code against a constrained interface and run it in a sandbox (useful for larger surfaces and multi-step logic).
Gateways are configurable and extensible. You can create new gateways, experiment with different strategies, and adopt whichever one fits your latency/cost/accuracy constraints.

Over time, teams stop thinking in one-off agents and start building reusable components. Two things matter here:
Because gateways can choose what to expose, they can also become a way to curate and bundle tools from multiple MCP servers into a single "virtual MCP."
That's useful even before you have a full app framework:
This bundling/curation logic is also how we think about MCP apps (coming soon): packaging durable capabilities that can be shared across teams—and eventually distributed more broadly through a store.
At enterprise scale, tools change constantly—vendors, internal systems, schemas, ownership. If every app is coupled to a specific MCP implementation, your agentic layer becomes brittle.
Bindings define contracts for common capability types (collections, agents, workflows), so apps can target the contract instead of the provider. Swap the MCP behind the interface, keep your UIs and workflows intact.
a standard interface for "things that contain other things."
a standard interface for AI agents, independent of provider.
a standard interface for deterministic multi-tool orchestration.
(We'll go deeper on agent/workflow bindings in a future post.)
With contracts and shared interfaces, the same application code can work across teams with different permissions and toolsets—without branching your system into per-team variants.
There's a tension we keep seeing: build everything yourself, or integrate a dozen tools and live with sprawl.
Our approach is to centralize the infrastructure you shouldn't rebuild repeatedly—connections, governance, observability, routing, cost controls—while keeping the edges composable. When a strong MCP server appears (vendor, internal, open source), you can adopt it. When you need something domain-specific, you can build it. When implementations change, your contracts can stay stable.
The interesting part is what happens over time: your investment compounds instead of fragmenting.
Available Now (Q4 2025):
Coming up Q1 2026:
Feedback from our clients and community shape this roadmap.
npx @decocms/meshThe MCP Mesh solves the immediate infrastructure problems teams hit when MCP moves into production: sprawl, missing visibility, inconsistent policies, and costs without attribution.
More importantly, it makes the next step practical: turning one-off agent setups into reusable capabilities that can be packaged, governed, and shared—without rewriting integrations every time.
Subscribe to our newsletter and get the latest updates, tips, and exclusive content delivered straight to your inbox.


